这一节讲如何将得到的feature或hypothesis组合起来用于预测。
1. 林老师给出了几种方法

在选择g时,需要选择一个很强的g来确保Eval最小,但如果每个g都很弱该怎么办呢

这个时候可以选择Aggregation的方式将这些若g组合起来,组合起来的G,既能feature transform又能regularization这一对矛盾的性质。
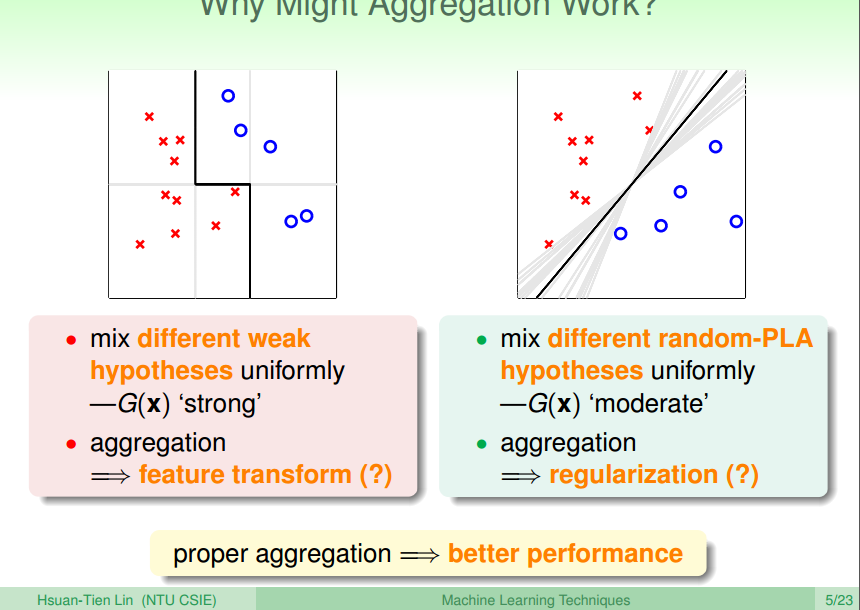
2.接着讲了用uniform blending的方式来classification或regression,并推导了使用uniform blending的好处:Eout更小

接着解释了上述不等式的物理意义:一个算法的期望表现,等于consensus的表现加上consensus期望的偏差,通过uniform blending来消除variance。

3.接下来讲的是linear blending.
采用这种方式的一个问题是overfitting。对此,林老师的建议是,选择的时候,blending要在validation上做。

下面仍然是介绍如何避免overfitting,可以用非线性model,但没听懂,泪。。。。

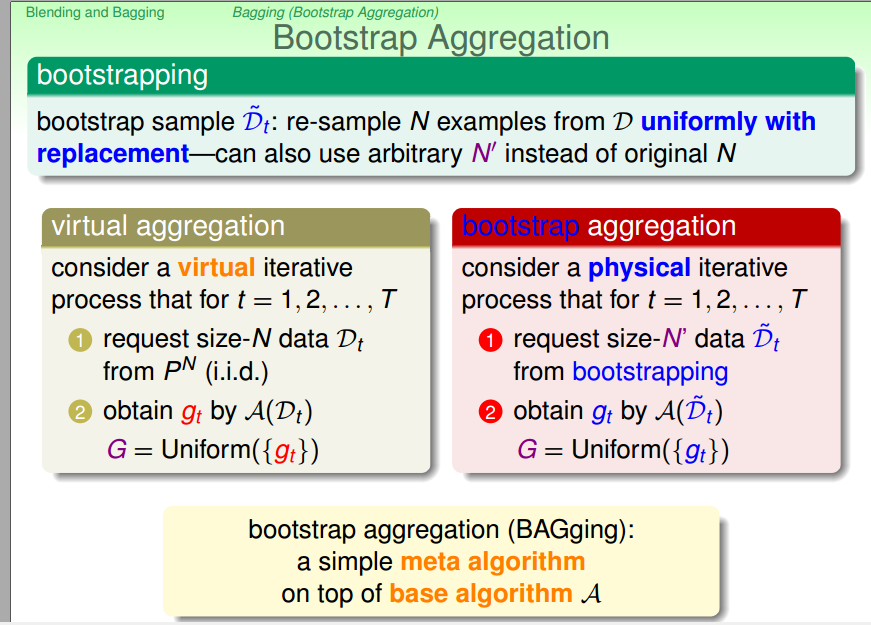
4.接下来讲的是如何得到不同的g。

接下来介绍了一种方法bootstrapping:为了得到不同的g,对数据资料进行放回抽取,对每小份资料进行学习得到g
这位博主也总结了下,可参考:http://blog.csdn.net/lg1259156776/article/details/46821389